



First, I’d like to express my thanks to Jie Shang and Alexander Summerauer who helped in creating the content for this blog.
vRealize Automation is architected to manage globally spread infrastructures. Some customers use it to manage their resources in multiple locations within a distinct country by 1 vCenter, some customers have their infrastructures in different continents managed by multiple vCenter installations. All have in common that for provisioning of resources they mostly need to make sure that image cloning processes are done within a specific region to limit the transfer of large data across an often low-performing WAN connection with high latency. This however requires an architecture to transfer operating system images (templates) into the distinct location once and afterwards provision resources from there “locally”. Also, it needs to make sure that updates to the templates are automatically transferred to the regional target locations.
The vSphere content library has been developed to support this use case. While this is a vSphere related functionality, upper layer tools like vRealize Automation need to have some level of support leveraging it. In specific, vRealize Automation has included content library support since version 8.0. The integrated image mapping functionality is aware of content libraries and can refer to images hosted on those.
Digging deeper into the topic you will see that there are some dependencies on the vSphere architecture how to build up your content library. In this example I will focus on an environment with multiple vCenters that have no linked mode enabled in between.
Content libraries
Content library basics
Content libraries in general are vCenter-wide configurations. You can have multiple of them. There are 2 types of content libraries:
- Local libraries (which can be published)
- Subscribed libraries (which can receive content from a published library)
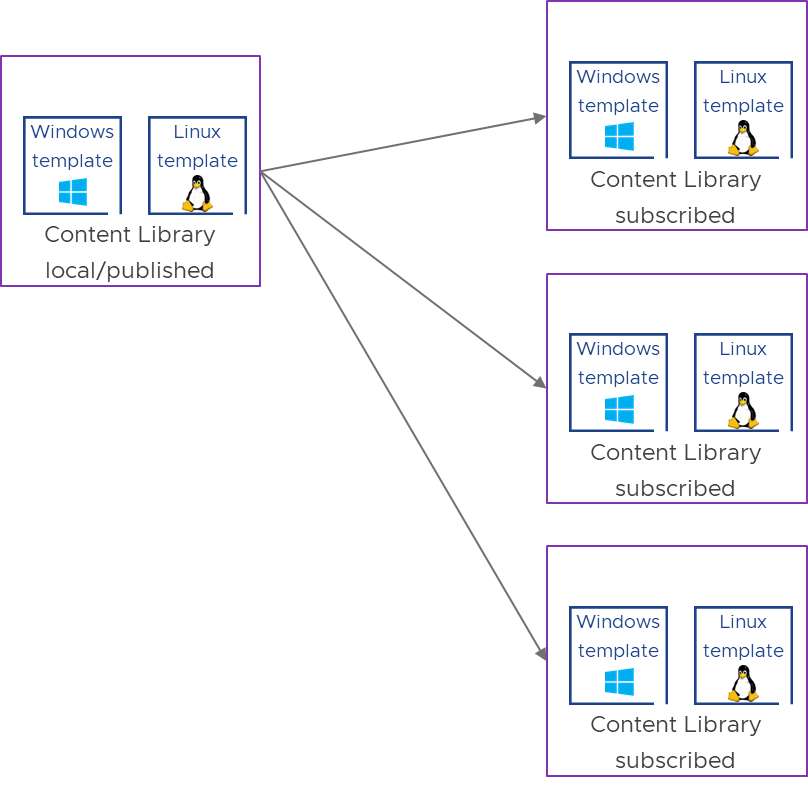
There can be multiple content libraries in one location, however each content library is configured to use a datastore for image store and/or management. The configured datastore controls where subsequent clone operations are executed from. As a best practice you should have one datastore per location to make sure that high volume clone operations are executed locally while the original image transfer is done once for each update through the WAN connection.
Content library template types
Content libraries support either VM templates or OVA/OVF templates. There are some differences of both solutions which are explained in the related documentation pages:
The VM Template as a Content Library Item
The most notable difference for our use case is that VM Templates require vCenters to be in linked mode while OVF/OVA templates can be replicated across vCenters even if they are not in linked mode. Also, OVF/OVA does support NFS and SMB for image storage as well. On the other side OVF/OVA libraries do not support storage clusters.
Due to these circumstances this blog keeps focus on the OVF/OVA template architecture.
Content library sync
No matter which architecture is selected, templates are always transferred completely from publisher to subscriber library. There is no functionality for now that detects changes and only transfers deltas. You must make sure that this is considered with the WAN connections you have.
From a sizing and scale perspective vCenter supports a maximum of 16 simultaneous sync operations like stated here:
vSphere 7.0 Configuration Limits
The sync parameters can be tailored in the Advanced content library section.
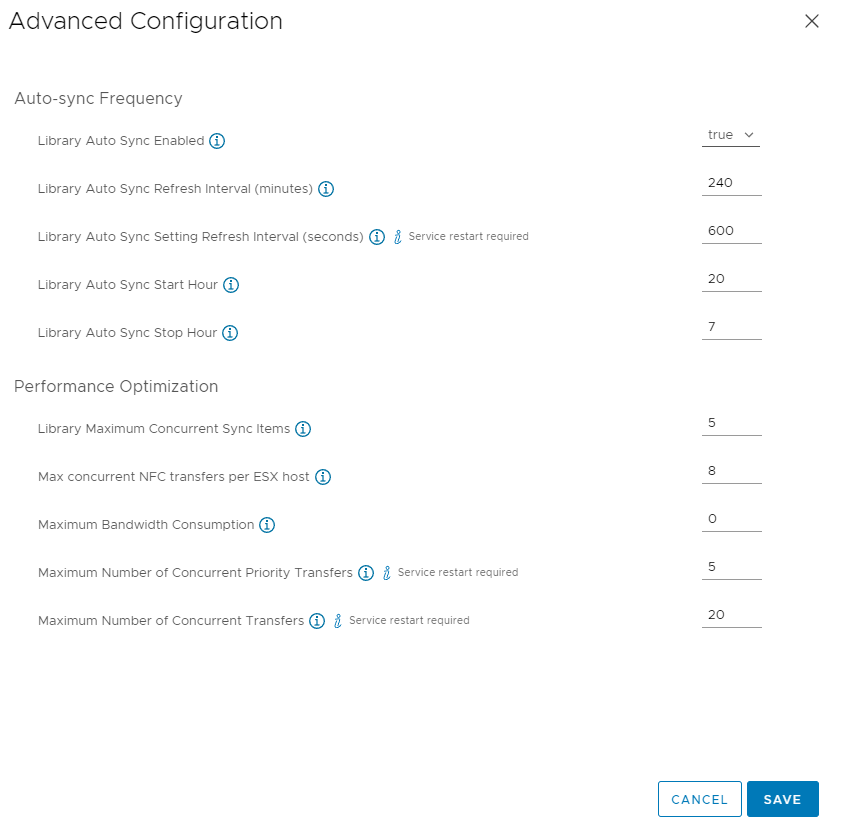
It might be advisable to modify the sync start and frequency of subscribed libraries in a larger scenario. Also, the maximum bandwidth consumption (by default unlimited) might help to control sync processes.
Content library scenario
In this blog we will focus on following content library scenario:
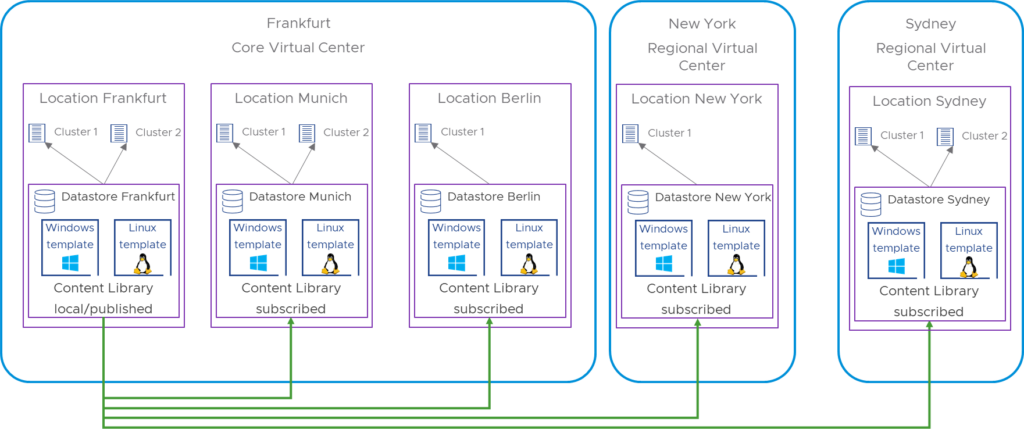
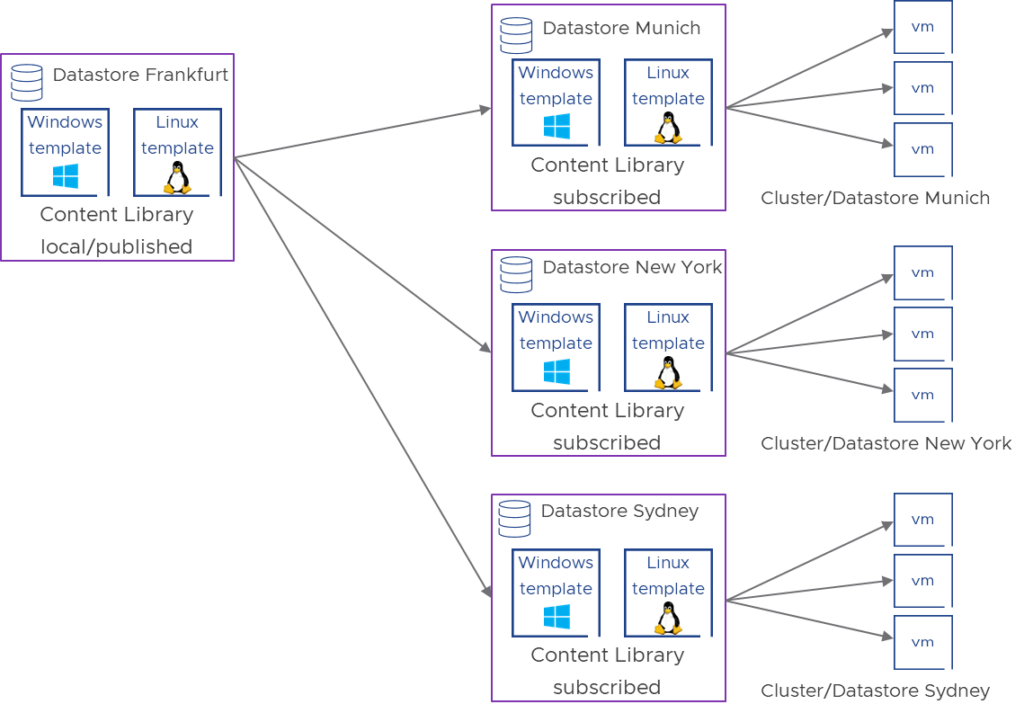
Typically, you would create a content library per location while multiple clusters on the same location will share this content library. This requires that in a location there is a shared datastore which can be attached to multiple clusters of the sake of hosting the content library. In this example, there is one published master library on Frankfurt Location and datastore. The other libraries are subscribed to the master and can be hosted in geographic distance. As an example, for the Munich location, it might host multiple clusters which are all connected to the same datastore where the templates are synced to from the publisher library. In theory, you could create a subscribed library and datastore per cluster, however, keep the max. simultaneous sync operations of 16 in mind.
Configuring a publisher library
You need to specify a name of the content library. If it is the master library, you can identify it by “master” in the name. Best practice would be to somehow add the location of the library into the naming convention.
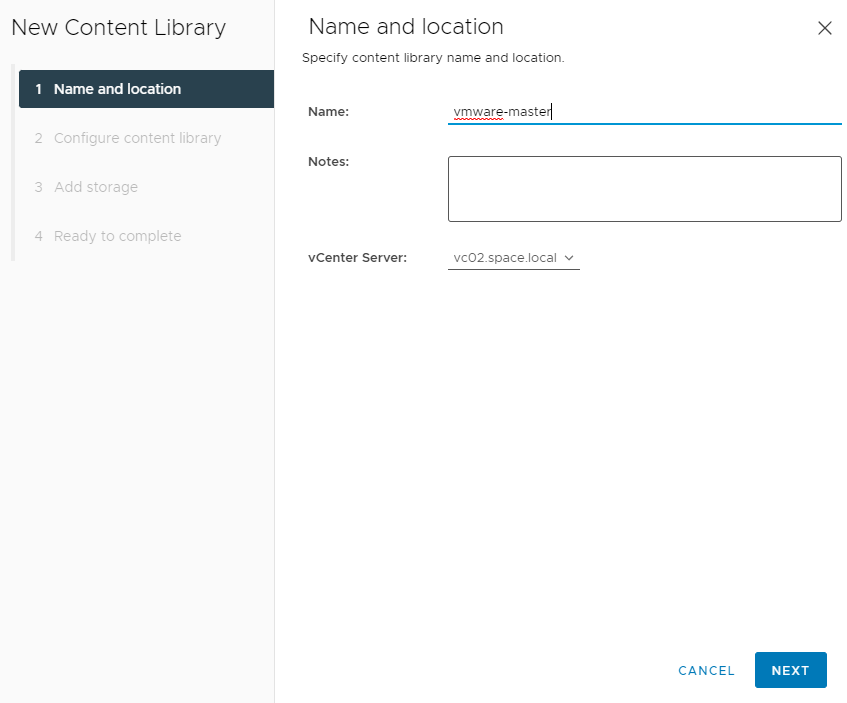
Next you will define this library as local library with publishing enabled. Optionally you can add authentication which is recommended. This prevents that somebody unknown who has the subscription URL available can subscribe to this library, sync content and create contention on the vCenter or WAN connection.
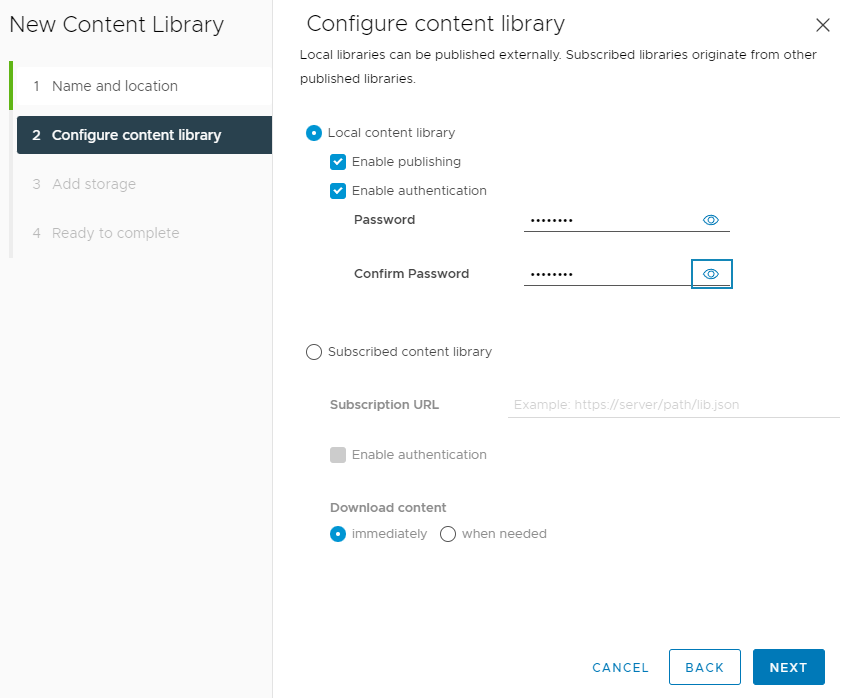
Optionally it is possible to apply a security policy which enforces validation of OVF imports.
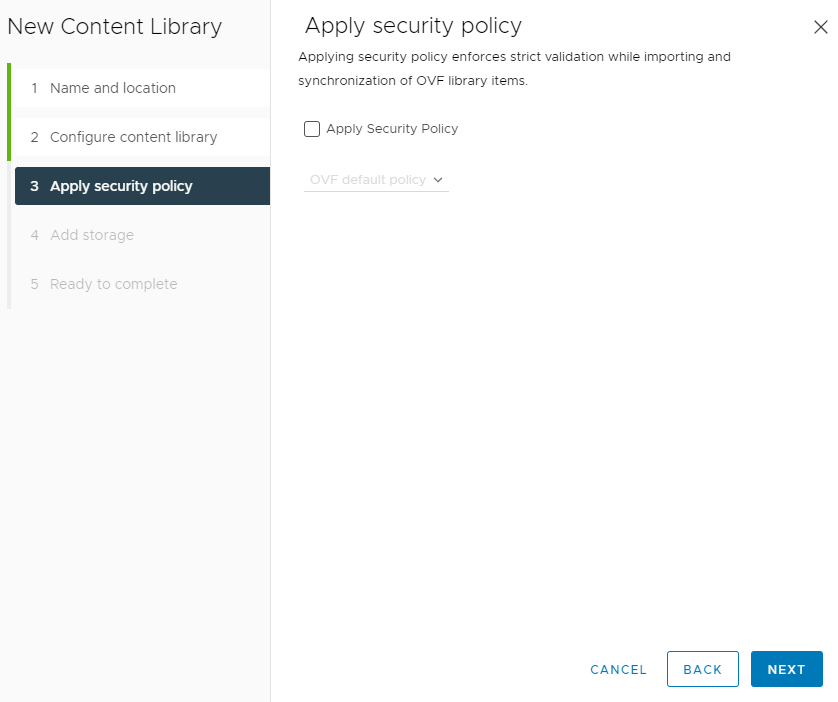
Finally, the underlying datastore must be defined. As mentioned, this defines where the images are stored that will be managed by this library.
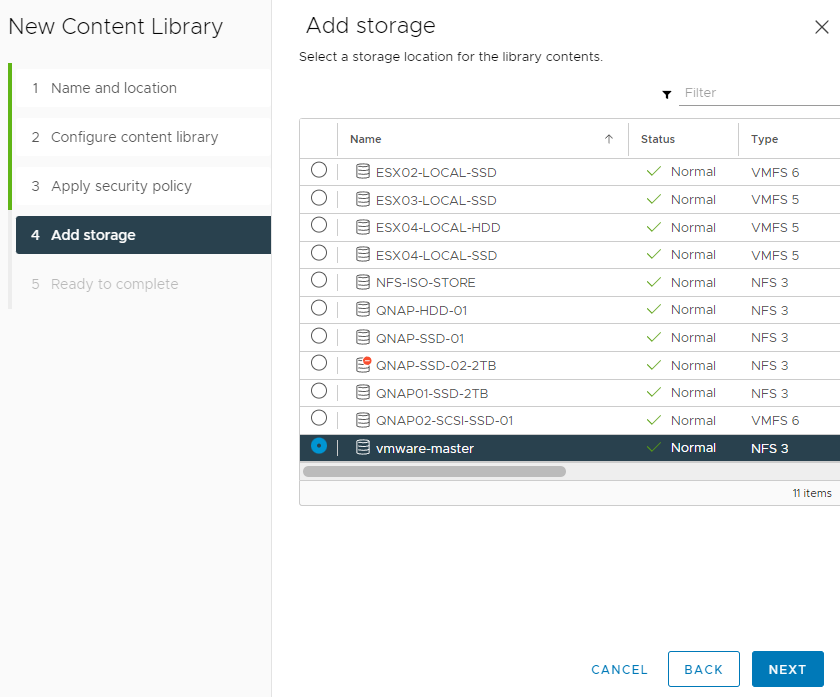
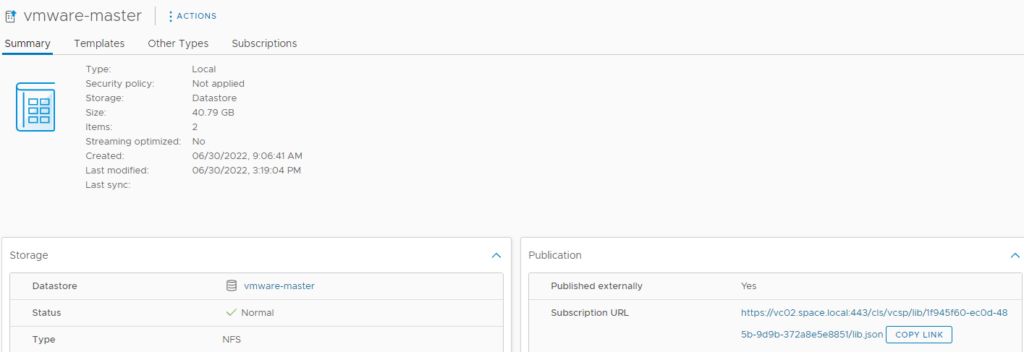
After successful creation of a master library, you have to go to the summary page of the object and copy the subscription URL. This URL is required in a later step to define where a publisher library should sync from.
Note: It’s important that this URL is kept 100% as is (e.g. don’t remove :443). vRealize Automation will check that URL and you will not work as expected if it is not the same.
Configuring a subscriber library
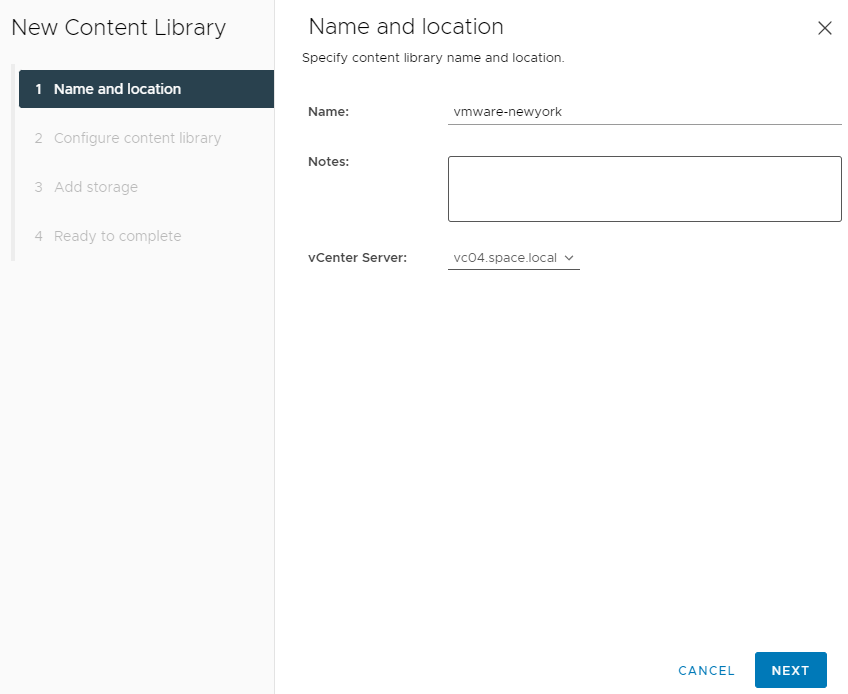
Specify a name of the content library. Like the master library it’s recommended to add the location in it.
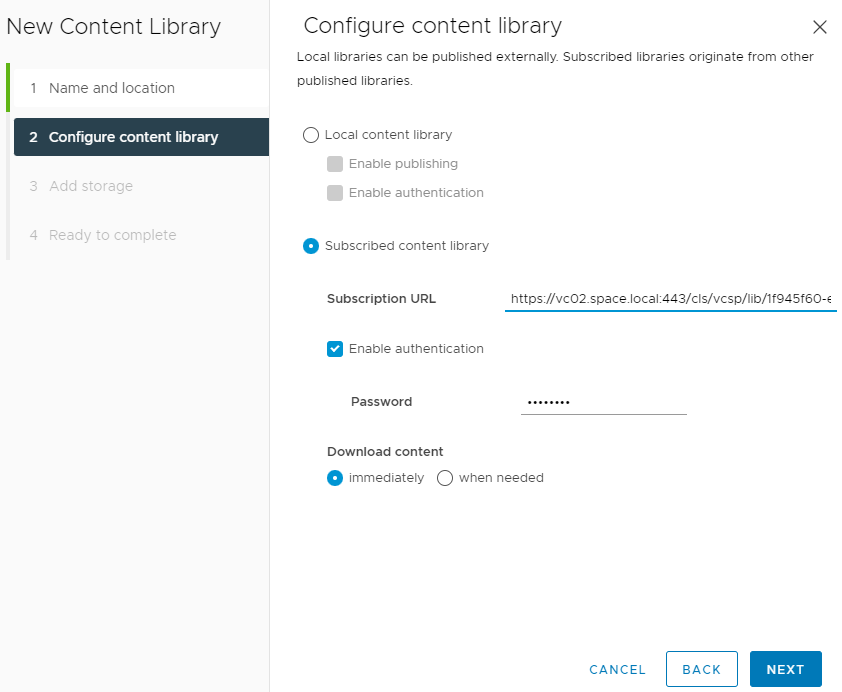
Select “subscribed content library” and add the before copied subscription URL in original. If authentication has been enabled on the publishing content library, the related password must be specified here. You can decide to download the content immediately or when needed. In a vRealize Automation scenario I would recommend setting it to “immediately” not causing delays on first image clone processes for the user.
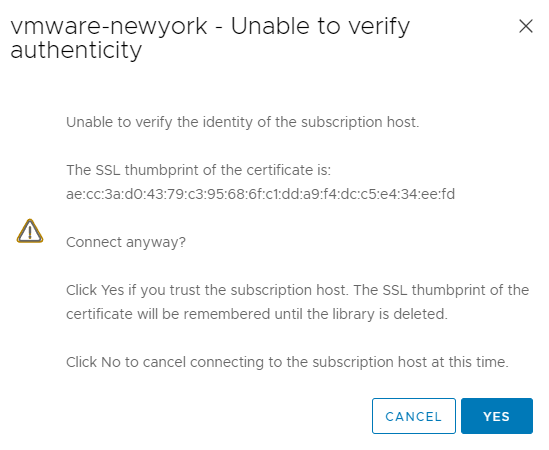
If the connection is successful, it will ask you for the vCenter certificate to accept (provided it’s an unknown certificate).
Same as with the publisher library the related datastore for the subscribed library is selected now.
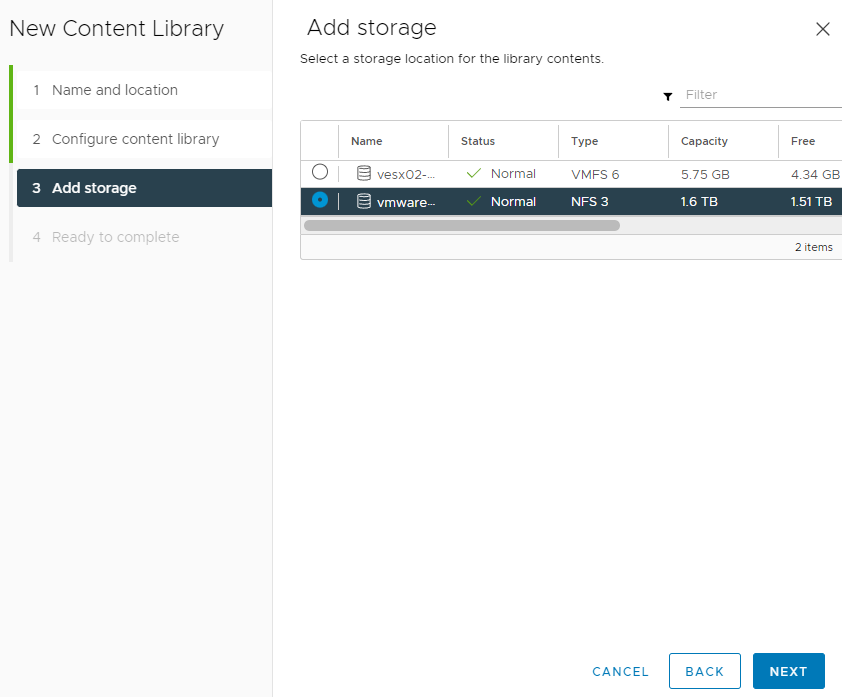
vRealize Automation with content libraries
In vRealize Automation 8.x the image sources are controlled by image mappings.
Before you configure the image mapping you must make sure that the image sync has run successfully. By default, this is done every 24 hours and can be checked and invoked manually on the cloud account configuration page.
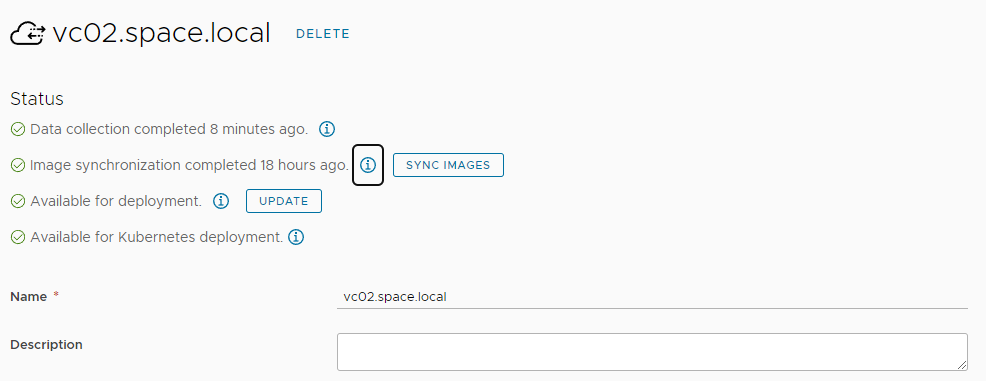
Once this has run successfully, the image mapping can be configured. Each cloud account / region is assigned an image mapping by an administrative task. If the content library is configured correctly, the image mapping should always show the image from the master / published library. Image paths to subscribed libraries should not show up on selection.
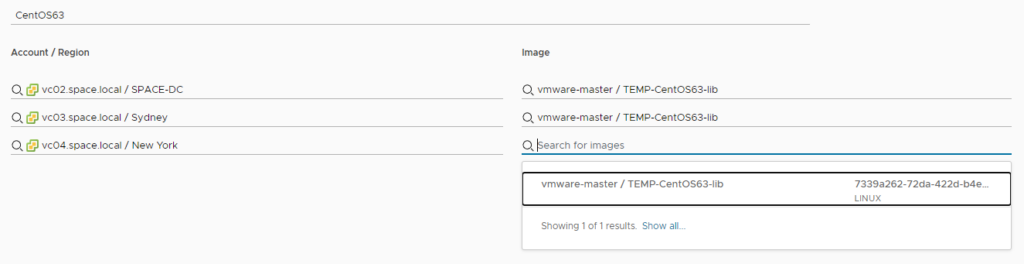
As a result, for a specific image mapping configuration (like CentOS 6.3 here) the image from the master library should be selected for all available accounts / regions.
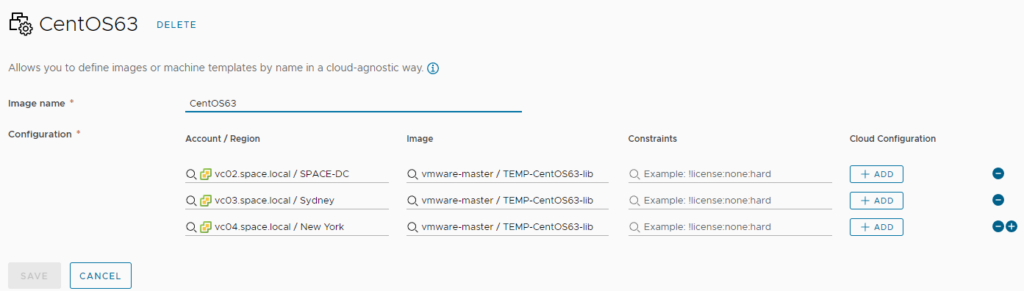
In case subscribed libraries show up here, you likely have a misconfiguration on the subscribed libraries specifically on the subscriber URL. Just make sure it is 100% identical to the master URL.
vRealize Automation has a logic in place that automatically detects the most efficient clone path for the target environment. Following sequence is used:
- Search if there is a subscriber content item for the same target datastore
- Search if there is a subscriber content item for the same host / cluster (depending on the target provisioning compute)
- Search the vCenter for a content item
Depending on what is found it ultimately could mean that a transfer is done through WAN connection, or the clone operation will fail.
Verifying deployment
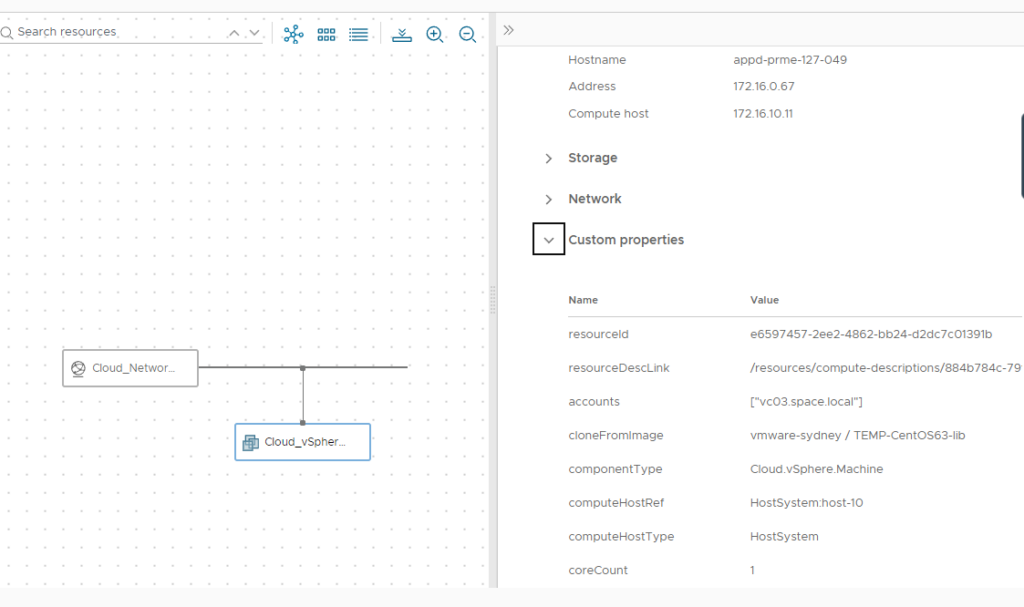
vCenter unfortunately does not have an easy way to verify where an image cloning process has been originated from. After successful deployment through vRA you can however check the deployment source as vRA maintains a “cloneFromImage” custom property. As you can see in the screenshot, the deployment of the image has been delivered by the “vmware-sydney” content library which is the proof that the vRA selection logic applied. Remember we configured the “vmware-master” library for the Sydney region in image mapping.
Have fun!

- 1-node Kubernetes Template for CentOS Stream 9 in VCF Automation - 30. September 2024
- Aria Automation custom resources with dynamic types - 9. August 2024
- Database-as-a-Service with Data Services Manager and Aria Automation - 4. July 2024
Hello
I understand and second the statement “put one CL per location”, but have a question regarding the visibility/accessibility of the storage. Instead of SAN, we have multiple vSAN clusters per location (which normally do *not* have access to the other cluster’s vSAN storage), yet deploying a CL template from cluster A (where the CL is stored) to cluster B works. So that statement depends on the storage used…
On the other hand, I read that this doesn’t work for CL ISOs (which need to be accessible by the VM itself).
So for multiple clusters in one location (interconnected by fast network instead of limited WAN connections), it makes no sense to put a subscribed CL on every cluster – one is sufficient (and saves space and WAN bandwidth), unless ISOs are used. Right?
Thanks for your comment! Be aware that this BLOG article relates to using Content Library in an Aria Automation environment. This might be different compared to a standalone operation. If you have a high bandwidth environment and don’t care about the actual data transferred for a potential cloning operation you are perfectly fine having a central content library. The big concern that has come up in the scenario explained in this blog is that there is clusters/datacenters with low bandwidth connection where the admin wants to make sure that a VM cloning operation is run locally as much as possible and does not go through WAN. This is why the configuration as suggested will make sense in this scenario.
On the ISO side I must admit I haven’t played a lot with it, so it’s up to your testing.