



English version: http://blogs.vmware.com/management/2016/05/minimalistic-os-monitoring-with-log-insight.html
Wenn man wissen will, ob ein Kind krank ist, misst man Fieber. Klar ist das keine perfekte Methode, aber eine verschnupfte Nase und die Temperatur reichen meist für eine Diagnose aus. Im Normalfall verzichtet man (noch) auf die Blutbildanalyse, Magen- und Darmspiegelung, Computertomografie und mikrobiologische Untersuchungen. Nicht dass mancher Arzt oder Mutter es nicht gerne täte.
Ähnlich pragmatisch kann man auch im ersten Schritt das Monitoring von Linux beschränken. Erst ein mal, will man die Auslastung des Systems kennen. Eventuell noch das Swap-Verhalten. Dann vielleicht noch ein Paar IO-Werte. Vorausgesetzt Log Insight ist installiert und das System angebunden (eine kontinuierliche Ausscheidungsanalyse findet statt) – mit wenigen Griffen lässt sich Performancemonitoring einrichten. Wir fangen mal mit Fieber an:
Load-Werte in Log Insight visualisieren
Mit “sudo crontab -e” wählen wir einen Editor und fügen folgende Zeile zum Crontab hinzu:
*/1 * * * * /usr/bin/uptime | logger
Jede Minute wird das Kommando “uptime” ausgeführt und die Ausgabe wird in das syslog umgeleitet. Die Ausgabe sieht übrigens so aus:
May 13 12:27:01 ugurke root: 12:27:01 up 1 day, 21:12, 4 users, load average: 0.00, 0.06, 0.06
Sind die Systeme über syslog oder Log Insight Agent angebunden, werden wir in Kürze diese Zeilen auch dort sehen.
Nun brauchen wir nur noch die interessanten Felder zu markieren (users, load 1, load 5 und load 15) und zu extrahieren. Mit ein bisschen Gefühl und Null-Ahnung von regex bekommt man es auch hin: denn Log Insight zeigt ja an, ob das richtige Feld getroffen wurde. Da es in diesem Fall nicht vollautomatisch geschieht, anbei die Screenshots:

Nun brauchen wir “extracted fields” aus den Uptime-Ausgaben. Da es sich nicht gerade um übliche Meldungen handelt, müssen die Felder etwas per Hand optimiert werden, bis sie sowohl bei Linux als auch bei Mac greifen. Anbei die Beispiele zur Übung, aber wer faul ist, kann auch einfach weiter lesen und das Content Pack importieren.
Load1 :

Load5

Load15

Users:

Uptime / Days

In ein Paar Minuten können wir nun Dashboards zusammeklicken. Zum Beispiel das Maximum von Load1 in der Zeit visualisieren. Ob man nun runde (spline) oder spitze Kurven mag ist Geschmackssache:

Interessanter wird es, wenn die Load1 Kurve mit der Anzahl der User korreliert:

in diesem Beispiel sehe ich, dass ein neuer User eingeloggt (Schnupfen) ist und gleichzeitig die Load1-Kurve steigt (Fieber). Nun können wir schnell durch “View Event in Context” erforschen, woran es liegt.

Nun sind so einsame Kurven zwar schön, aber es geht noch viel bunter: der crontab-Eintrag, der die uptime-Ausgabe zum Logger schickt, könnte ja bei mehreren Linux-Systemen stehen. Damit hätten wir die Last von vielen Systemen auf einmal im Blick:

Importieren des Content-Packs:
Nun da wir die Felder haben und diese auch noch Dezimal sind, kann das Fiebermessen beginnen. Wenn Sie sich die Arbeit mit den Feldern ersparen wollen, können Sie auch gerne diese zusammen mit einem Beispiel-Dashboard importieren Uptime-Output-v1.2.vlcp_.zip.
- Zip-Datei herunterladen und Entpacken
- Oben Rechts Menü -> Content Packs auswählen
- Unten Links -> Content Packs importieren
- Option “Import in to my content” wählen (damit sind die Felder und die Dashboards direkt anpassbar.
Hier ist das fertige Beispieldashboard mit mehreren Linux und Mac Systemen:
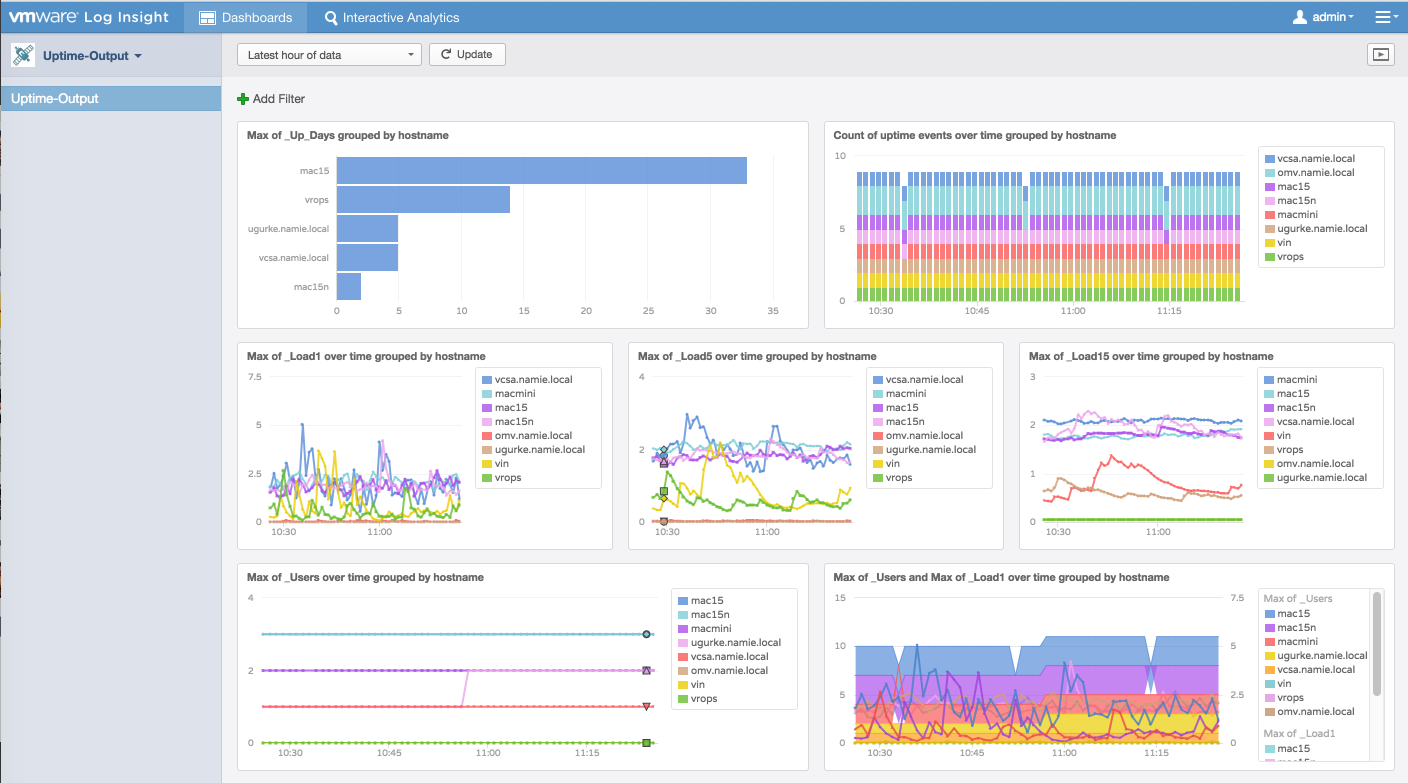
OS-Monitoring mit einem kleinen Skript:
Nun das “uptime” Kommando ist ja nur ein Beispiel. Andere Metriken können nach dem gleichen Prinzip in Log Insight visualisiert werden. Ein Erweiterung ist dieses kleine Skript:
CPU=`grep 'cpu ' /proc/stat | awk '{usage=($2+$4)*100/($2+$4+$5)} END {print usage}'`
LOAD_5=`cat /proc/loadavg| awk -F" " '{print $2}'`
MEM=`free | grep Mem | awk '{print $3/$2 * 100.0}'`
DISK=`df -lh | awk '{if ($6 == "/") { print $5 }}' | head -1 | cut -d'%' -f1`
/usr/bin/logger OS-Monitoring-tb:$HOSTNAME CPUINPERCENT=$CPU CPU5=$LOAD_5 MEMORYINPERCENT=$MEM ROOTFSINPERCENT=$DISK
#/bin/logger - für SUSE Linux
Die Ergebnisse sehen dann in Log Insight wie folgt aus:

Hello!
Field “_Users” does not work if the log contains the following line: “Mar 2 13:21:01 hostname root: 13:21:01 up 12 min, 0 users, load average: 0.01, 0.27, 0.22”.
But work if: “Mar 2 13:26:01 hostname root: 13:26:01 up 19:23, 1 user, load average: 0.01, 0.05, 0.05”.
Сan you fix the corresponding regular expression in the content pack?
Thank you in advance!